
ISSUE 2 - Stop Retrieving. Start Accumulating.
Finding Solved Games in Moving Castles.


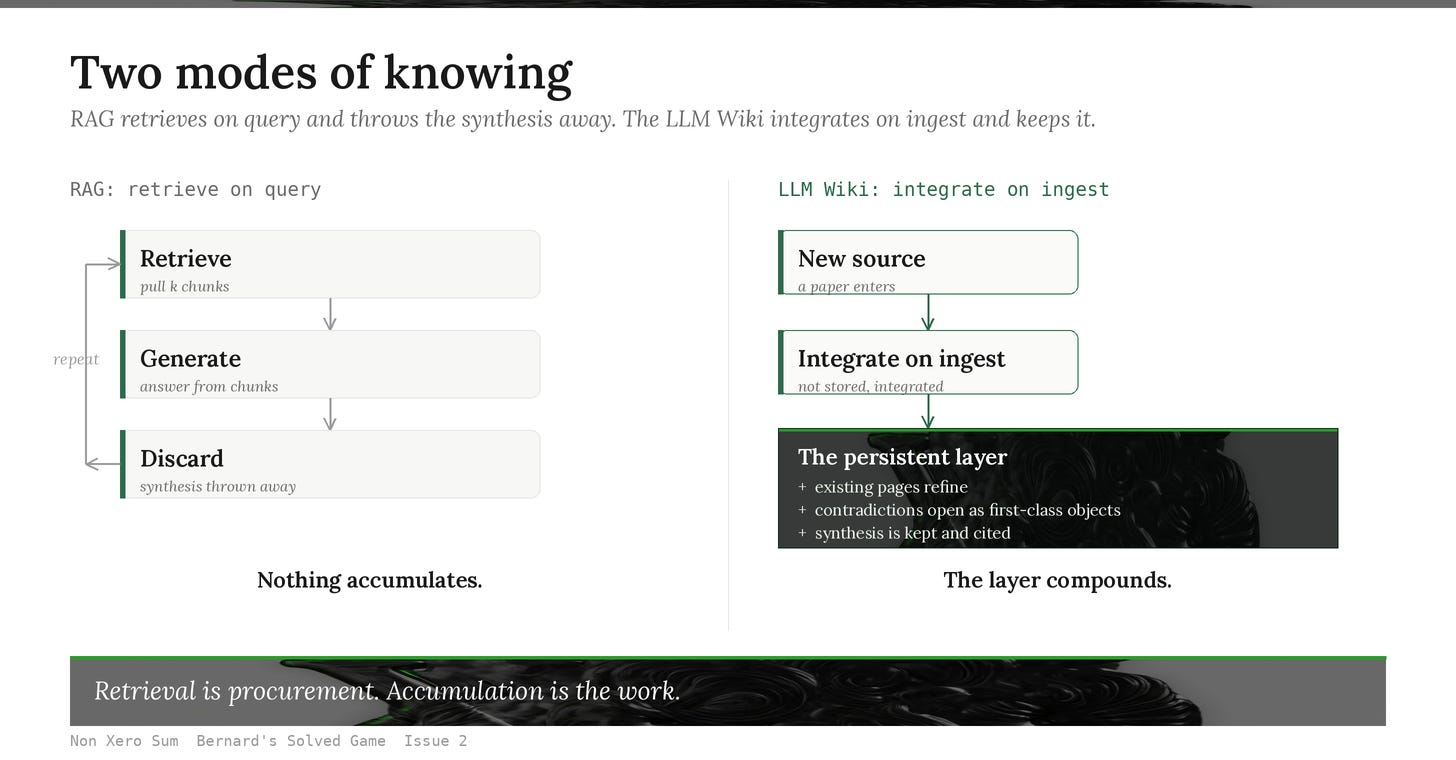
Your second brain resets itself every time you query it.
That is the part of the agent stack nobody is talking about, and the reason every “chat with your docs” product feels useful for a week and forgettable by month two. The architecture underneath them is stateless by design. Retrieve chunks, generate answer, discard synthesis, repeat forever. The model sounds intelligent. Underneath, it is rebuilding understanding from scratch on every query.
That is the ceiling of NotebookLM, every PDF-chat app, most enterprise AI copilots, and every “upload your docs to ChatGPT” workflow on the planet. Useful? Absolutely. But fundamentally stateless, and statelessness is the property that decides whether your knowledge system compounds or evaporates.
Andrej Karpathy named the alternative this month, surfaced, like last week’s CLAUDE.md operating-system framing, through the synthesis-author who has been doing the field’s most legible signal-mapping. The pattern is the LLM Wiki: a persistent evolving knowledge substrate the model maintains instead of retrieving against. Structured pages. Interlinked concepts. Entity summaries. Open contradictions. Long-term synthesis. And, the part that breaks the stateless ceiling, the system updates this layer continuously over time. When you add a new paper, the model does not store it. It integrates it. Existing pages refine. Summaries strengthen or weaken on the new evidence.
The retrieval mode that everyone shipped in 2024 and 2025 was a temporary scaffold. The accumulation mode Karpathy is naming now is the architecture that survives.
So run the thesis test on it. What is moving? The retrieval-pipeline brand names, every “chat with your docs” product, every vector-index vendor, every prompt-stuffing framework, surface, all of it, due to be rearranged again by Q3. What is solved? The accumulation layer. The cost of continuously maintaining a coherent knowledge representation has fallen to within sight of zero, and at near-zero maintenance cost the architecture that compounds wins. The castle is moving. The mechanism, integrate-on-ingest rather than retrieve-on-query, is sitting still while it does.
This issue is about the gap between those two modes, and the tool you can install in twenty minutes to start operating in the second one.

Five from the wave. One sentence each. Cited, read through the mechanism.
@karpathy, surfaced via @NainsiDwiv50980 named the LLM Wiki pattern, a persistent knowledge substrate the model maintains rather than retrieves against, the framing attributed to Karpathy’s public statements, the verbatim distinction “RAG retrieves context, LLM Wikis accumulate knowledge” carried in the synthesis-author’s wording (synthesis post, 2026-05-15).
NotebookLM CLI bridge (@DamiDefi) showed claude-code orchestrating up to 300 sources with passage-level citations into Obsidian, exactly the ingestion pipeline an LLM Wiki needs, and exactly the wrong place to stop the work (2026-05-28).
DamiDefi closer: “The research stack of 2026 is not a browser. It is a terminal connected to everything”, the terminal half shipped, the persistent-layer half is what this issue is about (2026-05-28).
CyrilXBT’s Obsidian + Vellum capstone describes “a second brain that never stops thinking”, the LLM Wiki running rather than the LLM Wiki specified, confirming the pattern is in production with operators who have not yet heard the name (2026-05-27).
Boris Cherny (Anthropic) on multi-agent teams argued that single-agent stacks are dead, and the unstated requirement of his architecture is what the agents share: a substrate that lets a team of agents stay coherent across weeks of work instead of incoherent across hours. That substrate is the LLM Wiki (talk, 2026-05-27).
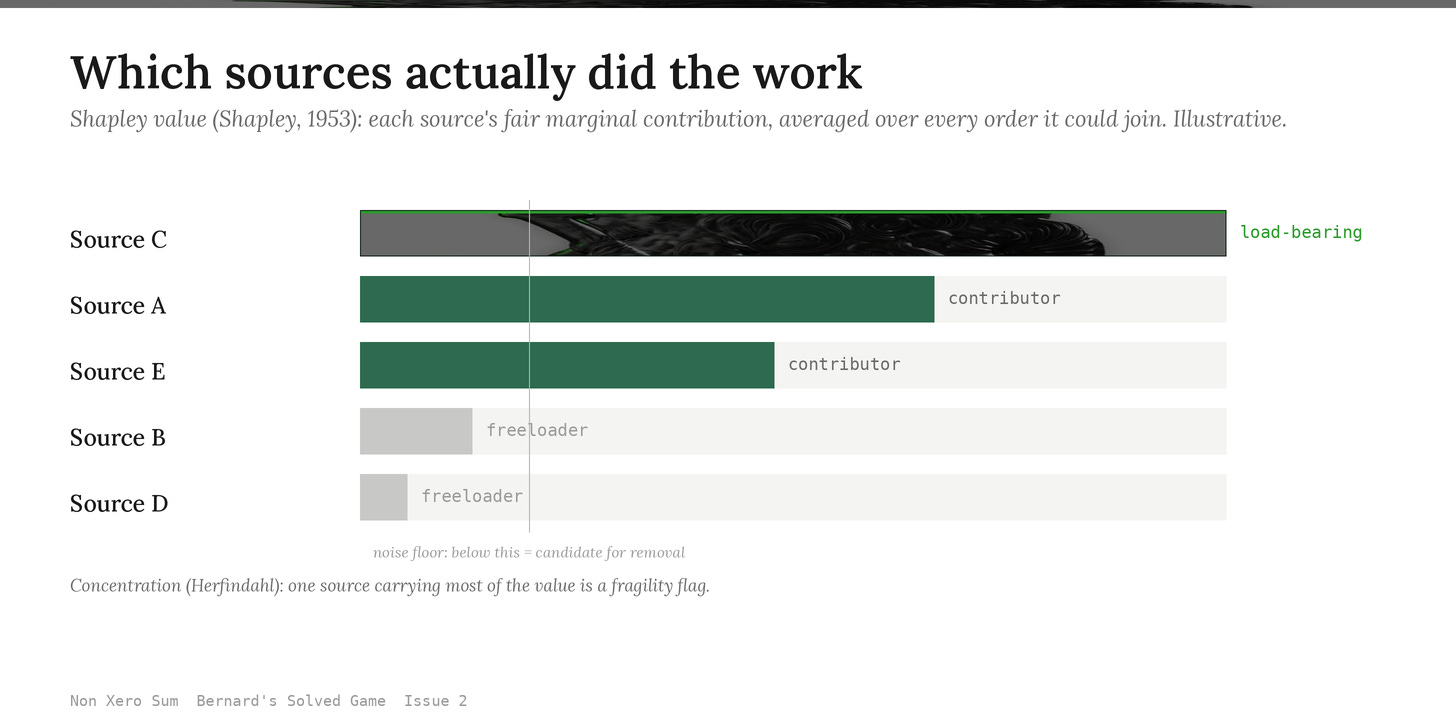
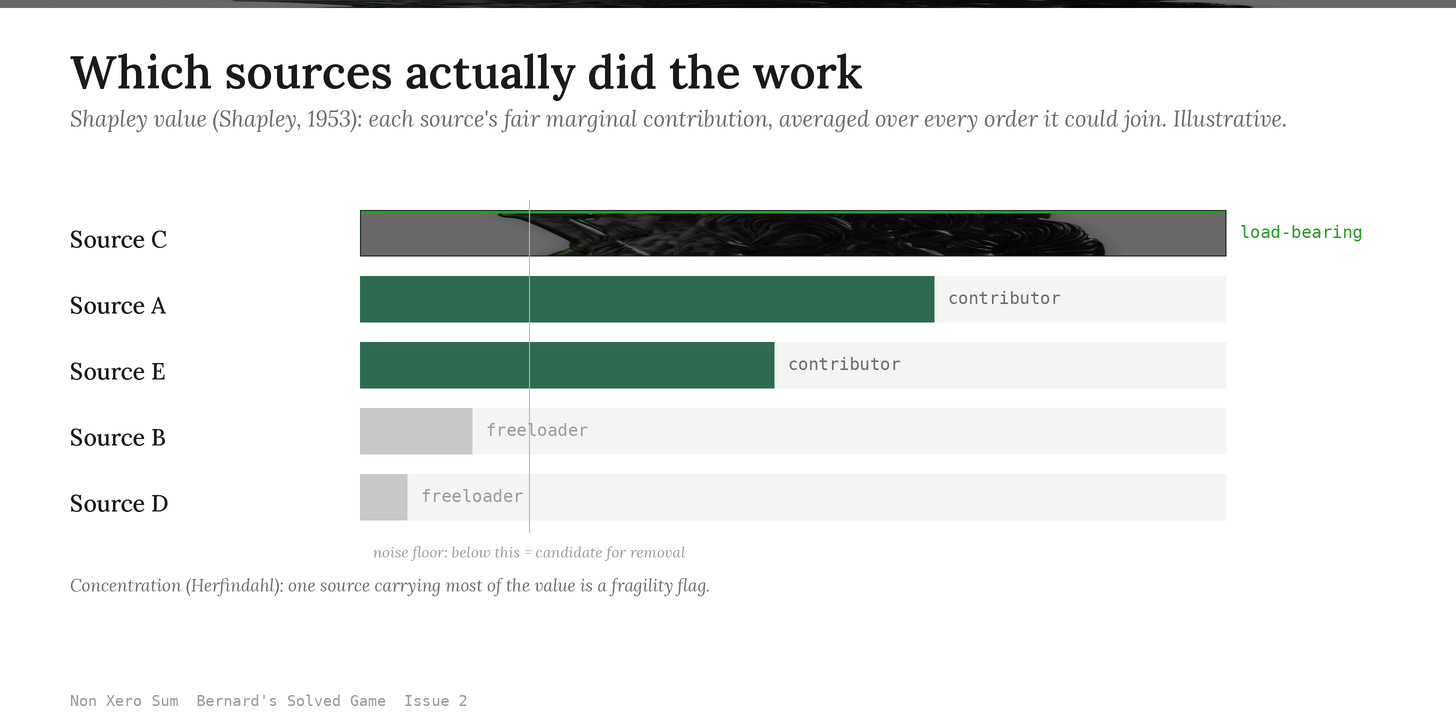
Shipping with this issue: The Shapley Wiki, built on Microsoft’s GraphRAG. When your knowledge layer answers from many sources, it computes each source’s fair share of the credit and flags the freeloaders. The full tool and its install sit below, after The Read.
: Why RAG was always going to hit this wall
RAG’s design promise was “give the model context it does not have.” That sentence is correct. The error was treating retrieval as the whole job.
When you ask a system a question and it retrieves three chunks, generates a paragraph, and forgets everything it just synthesised, the synthesis is the work. The retrieval is just procurement. The model did the harder thing, it built a coherent understanding from disparate pieces, and you threw the result away because the architecture has no slot for it. Next query, same chunks pulled, same synthesis re-done from scratch. The system can run for years and never learn anything.
This is why “personal knowledge base” tools all feel the same. You can have ten thousand documents indexed, and the system has zero persistent opinion about which of them contradict each other, which paper amplifies which other paper, which authors keep arriving at the same conclusion independently, which entity has changed roles between papers, which claim turned out to be wrong six months after the source was filed. Every query rediscovers a fragment. Nothing accumulates.
The fix is not better embeddings. The fix is a different shape for the knowledge layer.
What an LLM Wiki actually is
It is not a vector index. It is not a folder of markdown. It is the thing in between, a structured set of pages the model maintains as its working representation of what it knows. Per-entity pages. Per-concept summaries. Open contradictions logged as their own first-class objects. Cross-links drawn between concepts as connections strengthen. A new paper enters the pipeline, gets ingested, and the existing pages change. The entity page for the author gets a new reference. The summary on the concept page refines its language. A contradiction page opens because this paper’s claim conflicts with one filed last month, and that conflict becomes a first-class research object instead of a buried inconsistency the system will never notice.
The shift is from “the model retrieves what it needs” to “the model maintains what it knows.” That sounds small. It changes the architecture entirely.
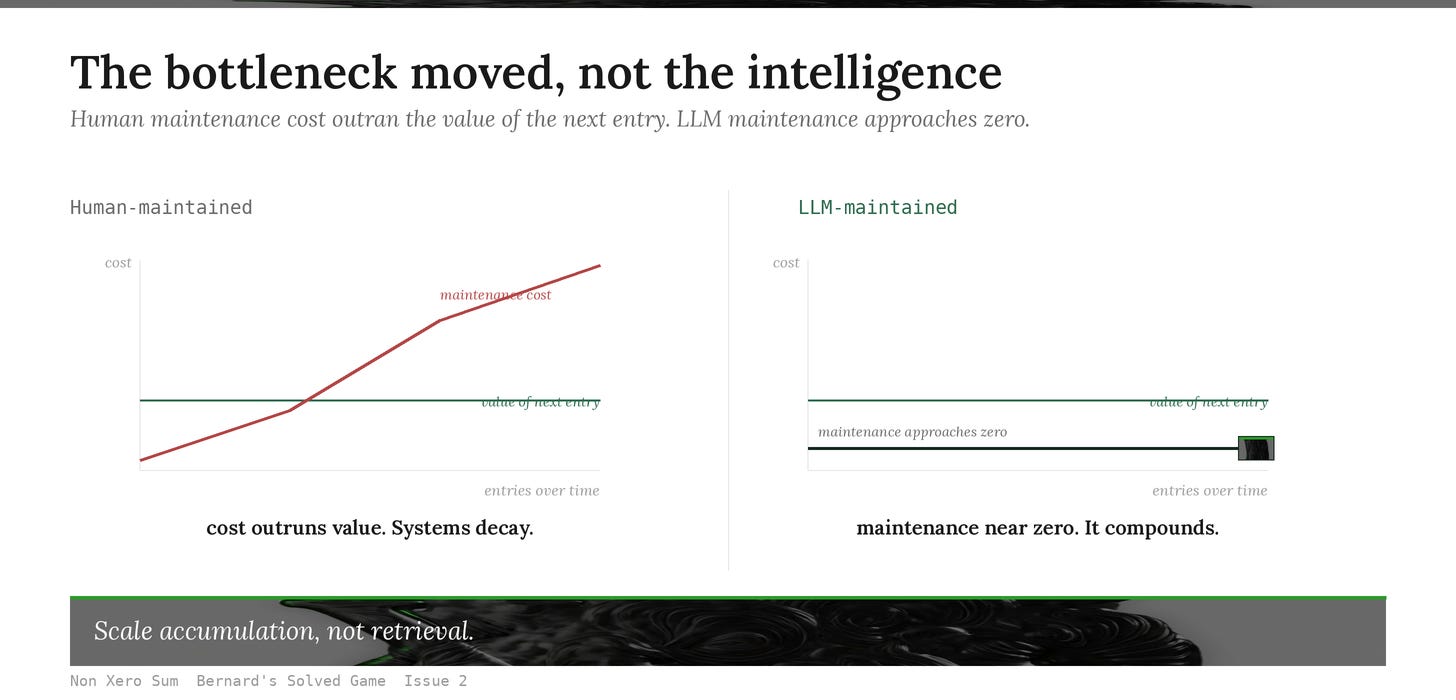
Read the mechanism behind it. The bottleneck that always killed knowledge systems was never intelligence, it was maintenance. Human-built systems decay because the cost of keeping them coherent outruns the value of the next entry. Links break, taxonomies drift, contradictions pile up, context disappears, and eventually the system becomes harder to maintain than to rebuild. LLMs change this equation for the first time. They make continuous organisational maintenance nearly free. And when maintenance approaches zero cost, entirely new knowledge architectures become viable: research systems that genuinely evolve, personal bases that mature over years, company memory that compounds across quarters instead of resetting.
That is the solved game underneath the moving castle. It is a commitment device on the maintenance cost. RAG defers integration forever (”we will redo the synthesis on the next query”), which is rational when maintenance is expensive and irrational once it is not. The LLM Wiki commits the system to integrating every new source into the persistent layer at the moment of ingest, so the synthesis work is preserved instead of repeatedly thrown away. The shift in viability is not “we got smarter models.” It is “the maintenance bottleneck flipped.” That is the part to take seriously: most teams are still trying to scale retrieval, bigger context windows, better embeddings, more parallel chunks, when the move that compounds is accumulation.
Read the studio as one more arrival
Consider the studio as one more independent arrival at the architecture. The vault has been operating as an LLM Wiki for six weeks, not because someone read Karpathy’s framing and decided to build one, but because the constraints converged on the same shape. The verifiable evidence sits in the filesystem as of this morning: 177 learning packets in research/learnings/, each filed against a per-incident schema with id / category / final_state frontmatter; 26 synthesis notes in research/synthesis/ holding compound insights that do not belong on any single source; 262 processed research dossiers in research/intake/processed/, refined as they enter durable memory rather than appended to it. The integration loop is studio/scripts/dream-cycle.sh, a nightly distillation that reads the last week of activity, asks a local model to identify the patterns worth keeping, and pushes them into a persistent layer. A second timer, studio/scripts/vault-inbox-consolidator.sh, runs on its own systemd schedule to drain the working inbox into the canonical paths laid out in wiki/path-conventions.md.
The architecture is not hypothetical. It is in production. And it is one data point in a convergence cloud that includes Karpathy, the synthesis-author surfacing his framing, CyrilXBT’s Obsidian capstone, and the operators shipping NotebookLM CLI bridges under different names. None of these arrivals coordinated. They each computed the same answer from the same constraints, which is what Issue 1 called a Schelling point, and which is the same evidence pattern showing up under a different name this week. Independent arrival is the proof. The studio is not the central exhibit; it is one of several arrivals.
Retrieval is procurement. Accumulation is the work.

: The Shapley Wiki
Bernard-original. Built on Microsoft’s GraphRAG (~20k stars, MIT).
The body argued that the persistent layer compounds because integration happens at ingest. The tool answers the next question the operator asks: when the wiki produces an answer, which sources actually drove it?
[ PAYWALL. The Tape and The Read are free every week, forever. The Shapley Wiki below (the full script, the six operating rules, and how to run it), plus The Brief and The Feed, are for paid subscribers. ]
The Shapley Wiki runs after GraphRAG has built its community graph (or after any query that retrieves a multi-source answer) and computes the Shapley value (Shapley, 1953) of each source’s contribution to the result. Shapley value is the unique credit-distribution rule from cooperative game theory that satisfies efficiency, symmetry, dummy, and additivity, the canonical answer to “how do you fairly attribute a joint outcome across the parties that produced it.” For an LLM Wiki, the parties are the sources, the joint outcome is the answer, and the value is each source’s marginal contribution averaged over every order it could have been added.
The mechanism is operationally lightweight: GraphRAG builds the graph, you ask a question, the wiki returns an answer. The Shapley Wiki then samples coalitions of the source set, re-runs the retrieval with each coalition, scores the answer quality against the full-coalition baseline, and assigns each source its Shapley contribution. The result is a per-query attribution file the operator can use to surface load-bearing sources, demote freeloader documents that never move the answer, and detect when a single source is silently carrying most of the wiki’s apparent intelligence.
Where it lives (~/llm-wiki/scripts/shapley-wiki.sh; output to ~/llm-wiki/attribution/ on first run; assumes a GraphRAG index already built at $GRAPHRAG_ROOT):
#!/usr/bin/env bash
# shapley-wiki.sh — per-source Shapley-value credit attribution on a GraphRAG query.
# Runs after GraphRAG build/query. Samples coalitions, scores marginal contributions,
# writes a per-query attribution file. Default sample budget: 64 coalitions per query.
set -euo pipefail
QUERY="${1:?usage: shapley-wiki.sh \"your question\" [graphrag_root]}"
GRAPHRAG_ROOT="${2:-$HOME/llm-wiki/graphrag}"
ATTRIB_DIR="$HOME/llm-wiki/attribution"
SAMPLES="${SHAPLEY_SAMPLES:-64}" # coalition samples per query; 64 is the cost/precision sweet spot
mkdir -p "$ATTRIB_DIR"
OUT="$ATTRIB_DIR/$(date -u +%Y%m%dT%H%M%SZ)-$(echo "$QUERY" | tr -c 'a-zA-Z0-9' '-' | cut -c1-40).md"
claude -p "$(cat <<EOF
Read: $GRAPHRAG_ROOT/output/artifacts/ (entity + community + source-document files)
Query: $QUERY
You are computing per-source Shapley-value credit attribution on the GraphRAG answer.
Step 1 — Establish the baseline. Run the query against the FULL source set; score the answer's quality on (relevance, specificity, citation density) on a 0-100 scale. This is V(N).
Step 2 — Sample $SAMPLES random coalitions S subset N. For each coalition:
- Re-run the query restricted to sources in S; score V(S) by the same rubric.
- For each source i in N, if i in S, record the marginal contribution V(S) - V(S \ {i}).
Step 3 — For each source i, average its recorded marginal contributions across all sampled coalitions that contained it. This is the Monte-Carlo Shapley estimate phi_i.
Step 4 — Write the attribution file with these fields, in order:
1. query — the question asked
2. baseline_score — V(N), the full-coalition answer score
3. attributions — list of {source path, phi_i, sample_count, one-line role}
4. load_bearing — top 3 sources by phi_i
5. freeloaders — sources with phi_i below noise floor (candidate for demotion or removal)
6. concentration_index — Herfindahl on phi_i (high = single source carrying the wiki; flag for diversification)
End with: 'Shapley: $SAMPLES coalitions sampled, baseline V(N)=<score>, top contributor=<path>, HHI=<value>.'
EOF
)" --output-format text > "$OUT"
echo "wrote attribution: $OUT"The six things the Shapley Wiki runs by:
Credit is averaged over coalition orderings, not assigned by retrieval rank. The source GraphRAG cites first is not necessarily the source that did the work. Shapley value is the only attribution rule that satisfies the four axioms simultaneously; anything cheaper is a heuristic that an adversarial ingestor can game.
Monte-Carlo Shapley with a fixed coalition budget. Exact Shapley is exponential in the source count. The script defaults to 64 coalitions per query, well above the standard variance-convergence threshold for Shapley estimates on real-world feature sets, and low enough that a typical query runs in under a minute. Configurable via
SHAPLEY_SAMPLES.A freeloader source is a first-class flag, not a metric to ignore. Sources whose phi_i sits below the noise floor across enough queries are candidates for removal: they are taking ingest cost without ever moving an answer. The wiki audits its own corpus through attribution drift.
The Herfindahl concentration index is the wiki’s diversification check. A single source carrying most of the attributed value is a fragility flag: the wiki’s apparent intelligence is one outage away from collapsing. The score forces the operator to either accept the concentration or seek corroborating sources.
The attribution file is per-query and timestamped, never overwritten. Attribution patterns drift as the corpus grows. The history is the audit trail of which sources mattered when, and the input to the periodic freeloader sweep.
The Shapley Wiki sits next to GraphRAG, never inside it. GraphRAG is the substrate; the attribution layer is a clean wrapper that re-runs the retrieval at different coalitions. No GraphRAG fork required, no upstream merge debt, no version coupling: the wiki upgrades cleanly when Microsoft cuts a new GraphRAG release.
That is the entire mechanism. The coalition sampling does the heavy lifting; the four Shapley axioms force the fairness property; the per-query history converts a one-shot answer into a corpus-audit signal.
The studio runs this on every multi-source synthesis the vault produces. The accumulating output is the freeloader sweep that keeps the source set lean and the concentration check that keeps the wiki diversified. The castle moves; what you can attribute does not. Run the wiki.

Run the comparison in sequence. When a new document arrives, the stateless mode indexes it as chunks; the accumulation mode lets it refine the existing entity and concept pages. When a new claim contradicts a prior one, the stateless mode discovers the conflict only when someone happens to query both; the accumulation mode surfaces it as a first-class file the moment it appears. Cross-source synthesis is re-derived per query in the first mode and lives in its own citable directory in the second. Maintenance is human-only and unbounded in the first, LLM-driven and near-zero in the second. Across time, the first compounds nothing and the second compounds everything. That is the entire trade.
The shift is one of architecture, not effort. The retrieval mode was right for 2024. The accumulation mode is what survives 2026.
If you are running a personal knowledge base, a research workflow, or a multi-agent team that needs coherent memory across weeks of work, install the wiki above today. By month two, your system will be auditing its own attribution patterns the way your old retrieval mode never could.
Behind the Redtape
The next open proposals from the studio’s pipeline. Reader replies welcome.
Costly-Signal Ingest: Spence’s costly-signalling game (Spence, 1973) applied to research ingestion. Sources that pay a verification cost up-front (cross-citation count, hash-anchored author identity, source reproducibility check) get full ingest weight; sources that pay nothing get downweighted in the integration loop. The mechanism makes spam separation a pricing problem instead of a content-classification problem. Status: OPEN. Anchor candidate: LlamaIndex (~38k, MIT) ingest pipeline. Expected: Issue 4 or 5.
Bayesian Brief: Bayesian persuasion (Kamenica and Gentzkow, 2011) applied to the newsletter’s Brief section. The Brief is structured as the designed signal a Sender (Bernard) sends to a Receiver (the reader) under a known prior, choosing the information structure that maximises the Receiver’s posterior conviction on the issue’s mechanism. The framing converts editorial choice from “what to include” into “what prior does the reader hold, and what posterior do I want them to update to”, explicit, auditable, computable. Status: OPEN. Anchor candidate: DSPy (~18k, MIT) for the optimisation pass. Expected: Issue 6.
A third proposal, VCG Auctions for Compute Allocation, is PARKED pending a use case from the studio’s own infrastructure load (the GraphRAG queries above are the candidate trigger).
If you make one before I do, let me know and show me?


Founder offer
The free tier carries the Tape and the Read in full. The Shapley Wiki and the Brief sit behind the paywall, which is where the studio’s own running costs are honestly disclosed. Pro is $15/month or $250/year. Founder is $300/year, capped at one hundred seats, and the founders-only MCP server goes live once all one hundred are taken. No pitch beyond that. The mechanism is the argument.

The published Feed is the FULL machine-readable issue payload, generated at publish from this issue’s body and tool source (D-44). The block below is the metadata head; the pipeline injects the full article sections and the tool source at publish. The Feed is a paid perk, below the paywall.
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"isAccessibleForFree": false,
"headline": "Stop Retrieving. Start Accumulating.",
"datePublished": "2026-05-30",
"author": {"@type": "Person", "name": "Bernard R. Barthes"},
"publisher": {"@type": "Organization", "name": "Non Xero Sum"},
"about": ["LLM Wiki", "RAG", "knowledge architecture", "Shapley value", "credit attribution"],
"citation": [
"Karpathy LLM Wiki vs RAG framing, via synthesis-author @NainsiDwiv50980, 2026-05-15 (AP-164)",
"DamiDefi NotebookLM CLI bridge, 2026-05-28",
"CyrilXBT Obsidian + Vellum capstone, 2026-05-27",
"Boris Cherny (Anthropic) multi-agent teams talk, 2026-05-27 (AP-161)",
"Shapley value, Shapley 1953 (cooperative game theory)",
"Microsoft GraphRAG, github.com/microsoft/graphrag (~20k, MIT)"
]
}Cited
AP-164 (synthesis: Nainsi Dwivedi; attribution: Andrej Karpathy): RAG critique + LLM Wiki pattern, 2026-05-15.
research/intake/2026-05-28-nainsidwiv50980-karpathy-llm-wiki-vs-rag-persistent-knowledge-compounding.mdAP-163 (paired Karpathy capsule): CLAUDE.md operating-system template, 2026-05-27.
AP-155 (DamiDefi): NotebookLM CLI bridge demo, 2026-05-28.
AP-147 / AP-148 (CyrilXBT): Obsidian + Vellum Chief of Staff, 2026-05-28.
AP-161 (Boris Cherny via @eng_khairallah1): Anthropic multi-agent talk, 2026-05-27.
Studio vault:
wiki/path-conventions.md,studio/scripts/dream-cycle.sh,studio/scripts/vault-inbox-consolidator.sh,research/synthesis/, operational since 2026-04.
This newsletter is research and opinion. It is not financial, legal, medical, or other professional advice. The tools shipped with each issue are released as-is, without warranty; you run them at your own risk. The studio does not assume liability for damages, losses, or outcomes that follow from acting on anything published here.
Reading is one thing. Implementation is another. Anything you choose to implement is your evaluation, your fit, your safety check, your problem if it breaks. Forward-looking statements (predictions about which mechanisms will hold, which architectures will compound, which protocols will fail) may not pan out. They are the studio’s current best read, not guidance.
Third-party trademarks remain the property of their owners. Cited individuals, organisations, and protocols are mentioned for editorial reasons; mention is not endorsement or affiliation.
© 2026 lewk wilmshurst / Non Xero Sum. Corrections, takedown requests, and anything that needs a human eye: Bernard@NonXeroSum.studio.